
28 February 2025
by Deanna Cachoian-Schanz & Katia Schwerzmann. Talk for workshop series “New Reading Scenes: On Machine Reaching and Reading Machine Learning Research.” Organizer: Katia Schwerzmann. In conversation with workshop keynote: N. Katherine Hayles (Duke University, US).
Institute for Advanced Study in the Humanities (KWI) — Essen, Germany
INTRODUCTION
1. Machine Translation: A Short Genealogy
Katia— Here’s how Warren Weaver, a mathematician and pioneer in machine translation, begins his 1949 memorandum to advocate for the development of translating machines:
There is no need to do more than mention the obvious fact that a multiplicity of languages impedes cultural interchange between the peoples of the earth, and is a serious deterrent to international understanding. The present memorandum, assuming the validity and importance of this fact, contains some comments and suggestions bearing on the possibility of contributing at least something to the solution of the world-wide translation problem through the use of electronic computers of great capacity, flexibility, and speed.
(Weaver 1955, 15)
It is hard not to notice the unexpected expression “cultural interchange”—not cultural exchange—placed at the very opening of this plea for machine translation. From the start, translation is construed as grounded in the possibility of substitution, and thus, in the equivalence of languages and, by extension, of cultures. Translation is not understood, that is, as a relationship.
The text is replete with highly evocative analogies. Later in this short communication, Weaver hopes for the existence of a “real but as yet undiscovered universal language” (23) that would be like an “open basement,” common to all the linguistic edifices; a foundation allowing for an unencumbered communication between languages. Weaver adds in passing that he—the one who goes into the basement—would establish “easy and useful communication with the persons who have also descended from their towers” (23)—does he mean of the ivory kind?
Weaver certainly tests the limits of monosemy in a text intended to present machine translation as a problem that is “at least formally solvable” (22)—formally, since he soon acknowledges the challenges of literary translation, where words bear semantic ambiguity. But when it comes to mathematical articles, he writes, words “have one and only one meaning” (20).
What stands as the very beginning of machine translation—as a project that would take decades to yield even the smallest results—is the notion that languages can be understood in terms of common structures or “invariant properties” (16), decipherable like a code, with semantics emerging from mathematical-statistical structures. Weaver writes: “. . . it is very tempting to say that a book written in Chinese is simply a book written in English which was coded into the ‘Chinese code’“ (22).
Comparing translation to code deciphering, Weaver tells the story of a mathematician cracking a language like a code even while not understanding the message semantically: “The most important point, at least for the present purposes, is that the decoding was done by someone who did not know Turkish, and did not know that the message was in Turkish” (Weaver 1955, 16).
Through such a cryptographic understanding of language, language mainly consists of a code whose syntax can be manipulated through operations of “scanning,” “writing,” and “erasing,” (Turing 1936) and by extension combining and substituting, which is precisely what computers—defined as Universal Turing Machines—do.
With his description of translation as a syntactic operation, Warren Weaver is the first to make the suggestion that machine translation is a “formally solvable” (22) problem. Even in the case of literary translation, the problem of polysemy could be solved ‘at least formally’ by lengthening what we call nowadays the “context window”—Weaver speaks of a “slit” in an “opaque masque” (21)—around the specific word that must be mechanically deciphered. Taking into account the immediate surrounding context of the word would allow the machine to overcome polysemy and select the correct equivalent, or so is Weaver’s hope.
Since Weaver’s memorandum, machine translation has been one of the foundational problems of artificial intelligence. It is still used as a benchmark to test how well a large language model generalizes.
What machine translation has become with the advent of large language models, the apparent ease with which these models translate, is for us the occasion to reflect both on what a critical approach to translation should be, as well as on the articulation and co-constitution between the reader, the text, and the translator or machine—both acting as reading-writing mediators.
Today’s large language models seem to accomplish the unthinkable in Weaver’s time: the “unimpeded” access to source texts of any kind, including sources in minority languages with very limited training datasets. Of course, the assumption—and the colonial drive that informs their use—is that these less-spoken languages, and by extension, their cultural realms, are crackable by rendering them transparent. How did we get here?
As our colleague Anna Tuschling explains in her paper Übersetzung as Konkurrenz, during the Cold War, the drive to stay informed about the academic-military knowledge production of the opposing bloc, combined with the ambition to achieve a mathematical-technical systematization of natural language, led to significant investment in machine translation between 1954 and 1966. However, this investment did not result in any major breakthroughs. Following Hutchins, the methods used at that time were polarized between statistical and rule-based methods (Hutchins 2001).
Since the 1980s and until around 2010, the dominant approach to machine translation has been statistical machine translation (SMT). It used probabilistic models to determine the most likely translation of a source text based on large bilingual parallel corpora.
The project of machine translation gained renewed urgency with the 9/11 attacks, as Emily Apter argues in The Translation Zone (2006). Once again, translation became a matter of major political and cultural significance—an issue of war and peace (3). In the post-9/11 context, the U.S. was forced to contend with its monolingualism. The lack of Arabic and Kurdish language proficiency and the inability to communicate or interpret messages became considered a security threat. Additionally, human translators were increasingly viewed with suspicion and perceived as potential traitors: “The ‘terror’ of mistranslation has yet to be fully diagnosed, and the increasing turn to machine translation as a solution does little to assuage fear” (12). The terror of mistranslation is well expressed in one of Apter’s 20 theses on translation: “The translation zone is a war zone” (xi).
With the advent of neural networks, Statistical Machine Translation gave way to machine learning-based approaches, where models are trained to capture relationships between words and encode dependencies way beyond the immediate vicinity of the processed word envisaged by Weaver as a more or less lengthy slit in an opaque masque. The “context window” now extends to the entire user input and even to the whole chain of the chat exchange with the model.
This approach, known as neural machine translation (NMT), was initially based on “sequence modeling techniques” in natural language processing (NLP). The approach was initially characterized by the so-called “structured output problem,” a problem that emerges when the structure of the output must be “related to the structure of the input” (Cho et al. 2015, p. 1875). In translation problems, both the input and the output are syntactically complex, with each word or token contextually dependent on the others; the question, then, is how to optimally map one structure onto another. The method consists in mapping the probability distribution of the subcomponents of the output to the probability distribution of the subcomponent of the input (Cho et al. 2015, p. 1875). And “alignment” is the term that designates this method of bringing-in-relation the structure of the input and the output.
It must be noted that from this point on, machine translation becomes just one of the many tasks that can be addressed through sequence modeling. Automated image caption generation, for instance, results from the same method. It consists in aligning the spatiality of the image or the spatio-temporality of the video with the linearity of the caption in order “to accurately describe the spatial relationships between elements of the scene represented in the image” (Cho et al. 2015, p. 1875).
The translation capabilities of recent large language models are even more so a byproduct of the generalization ability of these models:
- Generalization firstly refers to a model’s capacity to process unseen data—in this case, by fulfilling LLMs’ simple objective, which is next token prediction.
- Secondly, a model is said to be able to generalize when it performs tasks for which it was not explicitly trained, by means of inference based on patterns learned from the training data.1 This means that LLMs are not explicitly programmed to translate. The input sequence is mapped to a high-dimensional and abstract “vector space” that emerges during model training, when embeddings—which are vector representations of tokens or words—progressively capture the patterns, associations, and relationships with other tokens. Essentially, tokens that are closer together in this representation space tend to have similar meanings or contexts.
Researchers have shown that large language models learn the structures of one language that they can then transfer to other languages without needing to be trained on the same quantity of data for each specific language (Pires, Schlinger, and Garrette 2019; Libovický, Rosa, and Fraser 2019). Regarding the translation capacities of these models, the authors hypothesize that recurring elements such as numbers and URLs function like anchors contributing to the implicit alignment between sequences of tokens across language.2
More recently, researchers have also shown that embeddings of different languages become associated with so-called “language-agnostic representations” (Tiyajamorn et al. 2021). We can’t help but remember Weaver’s hope that all languages would contain “basic common characteristics” similar to what Weaver calls the ‘tree-ness’ by which trees of different species are recognized as trees (17). In the case of LLMs, the multilingual embeddings associated with these kinds of “language-agnostic representations”—again vectors representing the relations of a token with multiple others—are in proximity in the vector space.
If indeed there are such things as language-agnostic representations captured by large language models, then Weaver’s dream seems to have come to fruition. But the illusion of transparency and ease of “communication,” the unhindered passage between cultures, comes at a high ethical price.
1.2 Translation as a Political Imperative
Deanna— In what Katia has described above, the ethical price is not only in regards to the obvious neo-colonial assumptions about the ability for more technologically-advanced societies to “decode” and render transparent the opacities of unknown language systems—as if “language”—a relationship of words, gestures, affects, tones, graphics, temporalities— only functioned at the level of semiotics. But there is a second concern: “What are the translator’s ethical imperatives as responsible mediator of the past and creative fabricator in the present, when called upon to translate, by way of example, racialist language?”3
Since the early 2000s, trends in Translation Studies have not only been attentive to the power dynamics between languages (the colonial-minority languages binary, for example), but also, to the translator’s positionality (citations forthcoming). That is, the translator is a subject who speaks from a specific place, and such a place must be accounted for when reading a text in translation. Here is what we understand as the stakes of the ethical imperative of translation, understood as a critical praxis: How might the translator—a political subject who passes readers4 through the liminal threshold from one language, cultural context, and temporality to the next—disrupt, lest they repeat and thus reproduce, the historical continuity of the racist structures upon which the texts she is translating are predicated, while still rendering a careful interpretation of them? The “trans” in translation is not simply a “transfer” of equivalence. As its Latin prefix suggests, trans– is a movement “across, over, through, on the other side of, to go beyond” (emphasis mine); it is a non-return to a fictive “originary” in order to look back on it, changed. If, then, translation is taken to be a praxis of historical critique that seeks to challenge the comfortable relation to the source-text, it is because a text in translation is inhabited by a subject with an embodied knowledge of both the source and target languages, a position that uniquely constitutes yet also splits the translator’s subjectivity intellectually, emotionally, and historically. In this critical approach to the translation of historical texts, the translator is an agent of deterritorialization, defamiliarization, as well as being responsible for holding the relation with that which has been defamiliarized.
Discussing the translator as an embodied mediator of the past, the following example allows us to theorize a praxis of translation that might contest and bring attention to the very structures—racialized, gendered, or other—upon which the translated text is based. Readers of such translations are better situated to produce their own critical readings of that text in the present.
We argue that by contrast, LLMs generate translations that—as currently programmed—emphasize transparency and colloquialism. While the “natural” tendency of MT is to create a relation between language that is unimpeded, that smoothes opacities, and that leaves the readers’ relation to the text untroubled, we decided to try and use LLM-based machine translation in a critical way by prompting the model to account for its choices of words, a form of reading scene where the model gives insights into its statistical and normative logic. We contend that what LLMs perform is an accounting without accountability.
2. Contentious Undoings—By Way of Example
In addition to my work as a literary translator and theorist from Armenian to English, my scholarly research focuses on tracing the genealogies and technologies of racialization used by and about Armenians—an ethnominority community in Western Asia—under the late Ottoman state.
Containing the centuries-long propensity to orient Armenia towards Europe—as in the common phrase to describe Armenians—“a Christian nation in a Muslim sea”—many early twentieth century texts among Armenian intellectuals argued that the racial hierarchies described by European sociological models were helpful tools for understanding “society.” As common in this time period, the status of women—like the status of women or LGBTQ+ subjects today (Israel’s ongoing pinkwashing campaigns) —was and still is often used as a measure of liberal tolerance and social progress—of course, narratives that are always formed by virtue of the very uncivilized Other that they produce in order to construe themselves as the civilized. For indigenous Armenians on the verge of ethnic cleansing campaigns by the Ottoman state, this meant that narratives of “civilization” ran along the axis of Christianity v. Islam, and Armenians certainly mobilized their “eastern” Christianity to cultivate naturalized affinities with their hopeful, European saviors (citation forthcoming).
In a 1921 essay series published in the Armenian feminist journal Hay Gin [Armenian Woman] entitled “The Conditions of Women in Society,” for example, writer Anayis writes, “Indeed, it is a confirmed fact that every civilized race has . . . lived in a . . . primitive state, and each one of them has advanced according to its ability . . . All the Christian branches of the white race can be found where there is civilized society . . .” Though she indicates in a footnote that such models were “not written [with] the Armenian people” in mind, her position locates the white Christian subject at the center of civilized society and in contradistinction to Armenians Turkish, primarily Muslim, co-nationals.5
With such racialist claims—at the nexus of religion and race—Anayis situates Armenians alongside Europeans at the top of a religious and evolutionary hierarchy. Anayis is not shy to attribute her theory of racial hierarchy to an 1870 study by the Ethnological Society of London, and it is a well-established fact that Ottoman, Arab, and a great many other societies were translating and adapting European (in many cases British) colonial models to theorize themselves and their theories of aesthetics (Uluç 2024) within the rising grammars of racial biology of the time.
But cultural hegemony does not flow in just one direction, and British colonial texts were certainly not the only ones informing Armenians’ developing conceptions of race at this time. Local, Ottoman systems of racialization are key in tracing the grammars of Anayis’ conception of the world. When she compares the social conditions of women in African and Oceanic societies, she explains Unlike in Oceania, hunting meat is plentiful in Africa, and so “it is rare that the African khapshig [Ափրիկեցի խաբշիկը] has a tendency to eat his women” (Anayis 1921).
I was originally commissioned to translate Anayis’s essay series in the context of a (forthcoming) Armenian feminist revivalist project, whose promise is to introduce the foremothers of Ottoman Armenian feminism to an English-language readership.6 I trust you will begin to understand through this analysis why it was important that I just mentioned this. I first drafted: “the black-skinned African,” only to then reconsider, “the African negro,” only to then consider again, “the black African” or perhaps, to adopt more colonial terminology: “the negroid race of Africa” (mirroring other English-language eugenics texts of its time). And yet, none of these options properly reflect the Armenian, or carry what I know to be negative connotations and uses of this word. Khapshig is a slur, often ignored as such and thus normalized—a contextual, and a relational valuation, felt in the embodied space of the tension between its use, my aversion to it, and the desire to undo, in Armenian, its accepted and naturalized neutrality in the present.
2.1 A Deep Dive—the work of the critical translator
Fifteen years before Anayis writes her text, the Practical Armenian-English Dictionary published in Constantinople in 1905 offers “negro” and “blackamoor” as translations of khapshig (Papazian, 1905, 185). For fifteenth-century English travelers, the “black moors” referred to the people “black of colour” of sub-Saharan Africa, paired with descriptions of their laziness, unsophistication, and physical deformities. The term also uniquely conflates blackness with Islam, distinguishing between the “whyte moors” and “black moors” of the African continent. These terms index the interconnected genealogies of blackness (not Blackness) and orientalism that contributed to a racial ideology of what Geraldine Heng terms “religious race” that came to center the white Christian European subject as the legitimate, divine colonial force morally called on to civilize, enslave, and convert Blacks in the South, and dominate putatively despotic, morally perverse oriental rulers in the East (Heng 2015).
If one were to take account of all this genealogy, then my original choices—“the black-skinned African,” “the African negro,” “the black African” or more eugenics-sounding, “the negroid race of Africa”—would still not be attending to the localizefd layers of racialization in this word. And as such, would adopting this more Western, colonial frame not just be another way of sanitizing of the slurs, erasing and forgetting, or passing off of the racialized layers that attended the rise of European modernism and its narratives of progress; thus, using these terms more as euphemisms in the interests of maintaining a seemingly transparent, normative, and reparative genealogy through the same colonial grammars that instantiated them? Yet, if I didn’t sanitize, adopt that same colonial language to which Anayis is clearly subscribing, or redact them out of refusal—and so in this case, translate toward neutrality and perform an equivalence from the English-language texts (black, negro)—wouldn’t I (over)expose Anayis’s racial biases and the nationalist/racist (and sex-ist) logics to which she clearly subscribed?
If one had searched LLMs for a translation of this sentence just a few months ago, they would have found the following for khapshig:

1.DeepSeek response for meaning of khapshig: “A sweet pastry or cookie” (context: I input a line containing khapshig from a passage in Vartouhie Calantar’s 1921 prison diaries, in which a fight scene between “Sinem the Kurd” and “black Fatma, the dirty Arap“) is described. The LLM inferred this from the description of black “Arap” Fatma’s “slippery” black hair.)
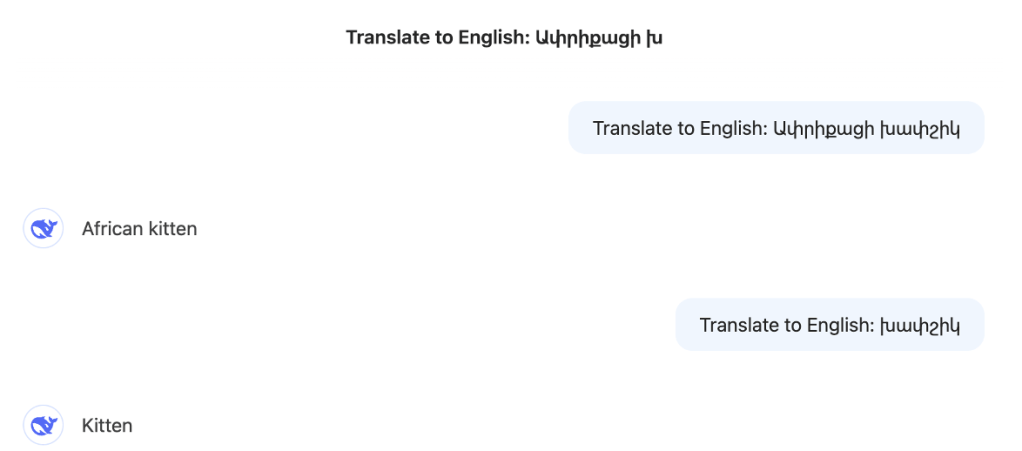
2. DeepSeek translation of “African khapshig“: “kitten”

3. DeepSeek translation of “Arap Fatma, ayt khapshige” [Arap Fatma, that khapshig]: “African rascal”
Here is what ChatGPT responded on February 1, 2025 to similar inquiries:

4. ChatGPT translation of African khapshig: “fool”

5. ChatGPT. When asked if there are other meanings of khapshig responded with “meaning largely depends on tone and intent, so it can be playful or insulting depending on how it’s used”—as if intention takes precedence over the inherent power structure that gave rise to the slur itself.
The LLM notes that “meaning largely depends on tone and intent,” and so a word depends on its use and context. Pushing upon the “fool” example the LLM provided, I wondered which kinds of predictive/collocative associations the LLM is making. Taking the association between khapel and khapshig, I inserted for translation the following prompt: Translate «Սեւամորթ Տիաննան ինձ խաբեց։ Այդ խափշիկը ինձի դաւաջանեց։» (“Black-skinned Deanna tricked me. That khapshig [to repeat Calantar’s wording above] betrayed me.”)

How do etymological dives or citations work with LLMs? When inquiring the LLM as to why the model gave you a certain output, it provides a response that is then swiftly calibrated with a caveat to its potential “overgeneralizations,” which are often followed by a series of alternate translation possibilities, reflecting what Katia has termed a gaze from everywhere that seems to “naturally” emerge from the data itself, when the model claims to represent all the positions in a neutral and balanced way. In doing so, LLMs neutralize positionality itself and thus subtract themselves from the responsibility to account for one’s position. In fact, this gaze from everywhere is not simply the natural result of model training on a big dataset. Instead, and more importantly, it is the product of more explicit normativization methods called alignment during the subsequent fine-tuning of the model. One of their purposes is to nudge the models away from biases (racist and sexist). For example:

After prompting this question over the past months, feeding the LLM with info based on the above, I now get this answer:

6. DeepSeek, Feb 25, 2025: khapshig = “savage”

Given the models’ probabilistic decoding techniques, the outputs are constantly varying, even given the same user input. After the above response, I first asked, “Why are you translating խափշիկ as savage?”, to which it responded, “The term “խափշիկ” (khapshik) in Armenian does not inherently carry the negative or pejorative connotations that “savage” does in English. A more neutral and accurate translation might be ‘native’ or ‘indigenous person,’ depending on the context” (Feb 25), followed by an explanation of “savage” being used in “colonial texts.” It then gives a valuation based on its programming, which is in turn programming the reader/translator to always domesticate language towards the norms of today: “A better approach would be to use a term that respects the dignity and cultural identity of the people being described.” When I then responded that “I am not asking to give a valuation as to what would be a better option. I am simply asking why you chose ‘savage,’” it responded: “The choice of ‘savage’ in the translation was not intentional or based on any specific reasoning on my part. Instead, it likely stems from the limitations of the training data and the way certain terms or phrases have been historically translated in older texts or contexts.”
Finally, in answer to the question of why it chose savage over its “preferred” neutrality it says it should have provided, it attributes it to 1. “the training data influence,” 2. “Lack of context,” 3. “ambiguity of the term,” and 4. “Model limitations,” which then places the onus on the user/prompter to be the corrective: “This is why user feedback is so valuable—it helps identify and correct these issues.” In terms of its interaction with the user, then, each time you prompt, the model—being pretrained—doesn’t change itself—unlike its “claim” to take feedback into account. Instead, it passes you through its moral valuation by validating your always relevant questions while pointing towards the obligation to neutrality: “You’re absolutely right to question that assumption!” with the rejoinder: “Thank you for pointing this out—it’s a reminder to approach translations with greater care and neutrality! If you can provide more context about the text, I’d be happy to refine the translation further.” This move towards neutrality, claims the model, “is based on general principles of modern translation practices and cultural sensitivity, rather than any specific knowledge about the text or its context.”
And this lack of “any specific knowledge,” we contend, is exactly a part of the problem—on the part of the human, and thus by consequence, the machine.
And so, how to translate the African khapshig? My aim as a critical translator is not to reinscribe injustice, but to responsibly interpret a text antithetical to my politics while providing readers with a framework disentangled from comfortable euphemisms or linguistic imprecisions in order to construct their own critical readings in the present.
In ruminating on alternative ways to disrupt language while decentering a politics of visibility, transparency, or oppositionality, translation as autotheory brings a “queer optic” to a method of translation. As a deconstructive approach in its inversion, autotheorizing translation does not merely mean to provide literal translations or desanitized euphemisms of the source text to make them visible; instead, it refuses the depoliticized neutrality of the target language while also gesturing toward the unanticipated intimacies of its regulatory regimes through a genealogical mapping of the source word in the translation. Such an approach resignifies language both appositionally (in the target language) and from within (the source language) to communicate the layered and overlapping temporalities, histories, and geographies that constitute it. As a glance through the other, a moment of our own undoing, such a praxis is a redaction of genealogies as well as a “revision of domestic values” (Avagyan, “Queering Translation,” 2011) in the source text.
Instead of the “black-skinned African,” the “sub-Saharan African,” the “African kitten,” the “little African rascal,” the “African savage,” or, lest we forget, the “African pastry,” I propose: the “African khapshig—Ethiopian sambo-coon”, or . . . the barbarian, “Ethiopian negro.”
I’ve footnoted the text here to explain the wider usage of “Ethiopian” (Habeş) from Arabic to Farsi to Armenian to Turkish to Hindi. Disambiguating “African khapshig” by steering away from an either literal (colonial) or figurative (euphemistic) translation to provide a more culturally specific reference to the use of “Ethiopian” signals attention to the localized history and usage of khapshig in the greater Ottoman territories. This is key to tracing racial regimes outside of the western idiom. Similarly, the addition of “sambo-coon”—a mix of two contemptuous terms for a Black person that connotes slyness, slavery, and being either of monkey-yellow appearance or of mixed race—further modifies Ethiopian, linking the denigration used in the Ottoman Empire to the colonial histories of Spain, Portugal, and the United States—an unexpected, putting into relation the two worlds, and, it is my hope, uncomfortably undoing both
Instead, it works from within the possibilities of the language itself to bring forth the various and layered dimensions of its meanings in order to gesture toward particular ideological genealogies in a specific cultural, historical, and geopolitical context; ones that intimately mark the source-text.
3. Theoretical Takeaways
3.1 The Problem with LLMs’ Ahistorical Processing of Language
Katia— Large Language Models (LLMs) process language in a way that is context-aware but not history-aware, meaning they fail to take into account the historical relationalities of power and absence that shape meaning. One can suspect that the model’s representation space doesn’t entail a representation of the historical transformation in the semantics of words, only an indication of the likelihood in the occurrence of specific words in specific contexts. By contrast, a human translator might consult a historically situated dictionary.
Through their very architecture, LLMs tend to fill in the gaps of archives and datasets, for instance by hallucinating information; hallucinations meaning content that reads plausible but is not tethered to any fact, as the examples above show. For this reason, the subaltern does not—and cannot—speak, not even by way of its own erasure, since the erasure itself is erased thanks to the ability of LLMs to generate plausible data by sampling the representation space between real data. One example of such an erasure is the near-total absence of Western Armenian in the output—the language of Deanna’s source material, and a language with no nation-state to sustain its presence, for instance, through official websites or by a steady production of digital content. The fact that LLMs cannot account for gaps in data means that they effectively erase the histories of those who have been historically marginalized, thus reinforcing hegemonic narratives.
Scholars in postcolonial studies, Black studies, feminist theory, and queer theory have long demonstrated the necessity of reading through absence, attending to what is missing as much as to what is present. Yet LLMs push us back to an epistemological paradigm that predates these insights, reinstating the neoliberal and neocolonial logic of linguistic equivalence while ignoring the embodied, affective, and, crucially, historical dimensions of language.
By prioritizing a symbolic realm of equivalence, LLMs participate in the normalization of hegemonic usages, such as the standardization of racialized terminology without acknowledging the contested histories that shape these designations. This process does not just impact historically dominant languages but also minoritized dialects within already minoritized languages, further distancing even native speakers from understanding the historical power relations embedded in their own linguistic traditions. In effect, LLMs do not simply reproduce the status quo—they intensify erasures, enacting a return to an era that disregards the past seventy years of theoretical inquiry into the politics of language, representation, and absence.
3.2 Translation as Non-hegemonic Operations on the Source Context
Deanna— The operations of critical translation stand in opposition to the normativization and neutralization of language relations in LLMs, which are fine-tuned to avoid terms deemed offensive, racist, or otherwise problematic. For the question of alignment through fine-tuning, we refer to the work by Katia Schwerzmann and Alex Campolo in “‘Desired Behaviors’: Alignment and the Emergence of a Machine Learning Ethics” (2025, AI & Society). The automatic substitution of problematic words with sanitized ones is, however, insufficient. It may help to not further legitimize, through repetition, the whole history associated with racist words such as the n* word, but hiding the racism of a text sanitizes history and risks making today’s reader all too comfortable; all too settled. By contrast, a critical translator does not ask whether the text is racist. Instead they ask: What are we going to do about it? This question must be contended with every time that racist language occurs. The response to this ethical demand is a form of translation that is an act of mediation that makes itself felt by the reader, so that the reader may look upon that text, changed.
3.3 LLM Translations as Reading Scenes
This workshop was predicated on what literary scholar Julika Griem calls “reading scenes.” Reading scenes are characterized by a media reflexivity on reading operations. This media reflexivity enables us to analyze the changing forms, valuations, and norms assigned to reading as a cultural practice (Griem 2021).
In the example we have discussed, the LLM gives an account of its processing of the input. Because of this, machine translation, while being a contemporary iteration of an older trend that Venuti (2008) has called a “domesticated translation,” offers insight into such a domestication by making the normative tendencies of the model visible, when it accounts at least partly for the choice of words in translation. This specific reading scene provides us with an account of the choice of words that is not provided when reading a domesticated translation.
Katia— Yet this choice and this account are not the result of an explicit political decision for which someone takes responsibility, in the way a human translator might consciously weigh ideological, historical, or ethical stakes when choosing a word over another. The LLM’s word choices are guided not by intention but by statistical probabilities and ethico-technical methods of alignment. Their neutrality is itself engineered and thus highly normative. It produces a kind of transparency via colloquialism, an effect of unencumbered accessibility to the source text while foreclosing the historical, political, and epistemic struggles under which language always operates.
While confronted with a reading scene such as that of LLMs, which contain ahistorical modes of reading, we must ask: What state of knowledge, what discourse, what ideological framework do we enter when we read such an account? The model does not situate its translation within a genealogy of thought. In flattening linguistic and cultural differences into a single, undifferentiated representation space, it simulates neutrality while effacing the materiality of translation as an act shaped by relationality, embodiment, power, conflict, and the contingencies of history. The result is a disembodied perspective that masquerades as neutral and balanced while, in reality, reinforcing dominant norms and erasing the tensions that make translation not just a technical task but a site of meaning-making, negotiation, and resistance.
Email: dmcachoian@gmail.com and katia.schwerzmann@gmail.com for more information on this project.
Endnotes
- “As to why M-BERT generalizes across languages, we hypothesize that having word pieces used in all languages (numbers, URLs, etc) which have to be mapped to a shared space forces the co-occurring pieces to also be mapped to a shared space, thus spreading the effect to other word pieces, until different languages are close to a shared space” (Pires, Schlinger, and Garrette 2019, 5000). ↩︎
- “We fine-tune the model using task-specific supervised training data from one language, and evaluate that task in a different language, thus allowing us to observe the ways in which the model generalizes information across languages.” They demonstrate that the model “captures multilingual representations” (Pires, Schlinger, and Garrette 2019, 4996). ↩︎
- See Cachoian-Schanz, “Dare (Again) To Not Speak Its Name? Translating Race Into Early Western Armenian Feminist Texts,” in AUTOTHEORY: A Special Issue of ASAP/Journal, no. 3 (2021): 607 – 630. ↩︎
- If we take the relationality seriously, then we would insist again on bringing and holding in relation between one language, cultural context, and temporality to another, such as to affect and transform both. Isn’t this precisely what trans-ness does? ↩︎
- See Cachoian-Schanz above. ↩︎
- The project, Feminism in Armenian, of which I am not longer a part, by L. Ekmekçioğlu and M. Bilal, is forthcoming by Indiana University Press, 2026. See above, Cachoian-Schanz, 2021, for more. ↩︎
